This article is about containers, the different types (depending on what privileges we let them have), and how they build their isolation: mainly kernel namespaces and capabilities, overlay filesystems, seccomp, and SELinux. My motivation to start this article was for me to understand a bit better how the combination of container isolation mechanisms and privileges affects (increasing or decreasing) the risk of kernel flaws.
I obtained a great part of the information from Michael Kerrisk videos on Youtube, but also from many sources included through the document and at the end of it. If I forgot to mention any source, please, let me know. Michael Kerrisk offers training. Consider it if you want to know more about Linux advanced programming, including Linux security and isolation APIs. He is a great great instructor.
Introduction
A container is a group of processes with some cool kernel features sprinkled on top [Jessica Greben’s definition]. Those kernel features allow the processes to pretend that they’re running on their own separate machine. While the host machine knows that the container is actually a set of processes, the container thinks that it is a separate machine.
The kernel features that allow this are:
- namespaces (NS): Make the container look and feel like it is in a different machine. For example, if you do a ps, the container will only see its processes. Different namespaces accomplish different segregation.
- cgroups: Group processes together and limit the resources they can consume.
- capabilities: Superuser privileges that can be enabled or disabled for the user within the container. A user within the container may perform some privileged actions, whether root or not.
- seccomp: Restricts which syscalls are available within the container.
- SELinux: helps avoiding something escaping from the container.
Additionally, filesystems take a key role in how containers are constructed.
Containers are usually used like a packaging mechanism that abstracts the code and all of its dependencies to make applications build fast and reliable [source].
The isolation between what is run within a container and the host is not perfect. There are points of interaction. If vulnerabilities appear in those points of interaction, the isolation can be broken, and something that is supposed to be isolated within a container may reach the host in unexpected ways. This is specially a risk for SaaS and PaaS services if some part of the security relies on the isolation of containers.
Rootful vs Rootless containers
A rootful container is a container run by root in the host. Since it is run by root, it has access to all the functionality that root has. This does not mean that any process executed within the container would be run as root. As we have said, the container engines implement some functionality, segregation, and limitations that try to control what a process within the container can do. We will see how containers implement these limitations.
However, at the end, if there is a vulnerability in the functionality that creates this isolation, the user within the container will be root on the host, and the compromise would be total.
Docker containers are usually run as root, however, it seems that it is possible to execute them rootless (https://docs.docker.com/engine/security/rootless/).
In order to have more security, an additional sound layer of security, someone thought it would be nice that the containers could be executed as a regular user. This is a challenge because the architecture of the containers was initially designed thinking that the user who executes them was root. However, with a lot of engineering and some tricks, rootless containers are possible.
A rootless container is a container that could be run without root privileges in the host. Docker runs containers launching them with the Docker daemon, which is run as root. Podman does not use any daemon and it does not need root to run containers.
“Rootless containers” does not mean that the user within the container is not root. It can be root, and by default it is, when using either Docker or Podman.
Related to security, the main benefit of rootless containers is that even if the container engine, runtime, or orchestrator is compromised, the attacker won’t gain root privileges on the host.
Rootless containers have limitations. Since they are executed as non-root, they don’t have access to all the features of the operating system. Some limitations are documented here https://github.com/containers/podman/blob/master/rootless.md. For example, you cannot publish a port below 1024.
Container isolation architecture
In this section, I’m going to enumerate how segregation is built for rootless containers, what kernel functionalities are used, and what are their effects on containers.
Namespaces
It is a kernel functionality that provides isolation of a resource. It accomplishes this by allowing the creation of different groups of processes and different groups of resources and then make each group of processes see only some group of resources. By default, only one namespace of each type is created and all processes can access all namespaces.
It could be seen as a very lightweight virtualization method.
There are 8 namespace kinds:
- Mount (mnt): isolates mount points.
- Process ID (pid): isolates process IDs.
- Network (net): isolates network stack.
- Interprocess Communication (ipc): isolates interprocess communication resources.
- UTS: isolates hostnames and domain names.
- User ID (user): isolates user and groups IDs.
- Control groups (cgroups): isolates cgroups.https://www.youtube.com/watch?v=0kJPa-1FuoI
- Time: isolates time (since kernel 5.6 Mar’20)
When the system boots up there exists one namespace of each kind, but multiple instances of each kind may exist on a system. Each process resides in one instance of each namespace. So, a bash process belongs to a mnt NS, a pid NS, a ipc NS, a UTS NS, a user NS, a cgroups NS and a Time NS. Each process only sees the resources that belong to its namespace.
You can create a process in a different namespace. When a process is created via fork(), it resides in the same namespace as its parent. With clone() + some flags, you can create processes in other namespaces.
$ hostname
localhost.localdomain
$ PS1='uns2# ' unshare -Ur -u bash
uns2# hostname
localhost.localdomain
uns2# hostname winterfell
uns2# hostname
winterfell
$ hostname
localhost.localdomainIn the example above, I have created a user namespace (-U), mapped the root user (-r) and created a UTS namespace (-u). I executed bash there. This uns2 bash shell is running in a different user namespace, and in a different UTS namespace than the host, but it belongs to the same other namespaces than the host. Only new user and UTS namespaces have been created, the rest are still shared.
It is possible to know in which namespace a process is by consulting these links with readlink.
/proc/<PID>/ns/mnt
/proc/<PID>/ns/pid
/proc/<PID>/ns/net
/proc/<PID>/ns/ipc
/proc/<PID>/ns/uts
/proc/<PID>/ns/user
/proc/<PID>/ns/cgroups
/proc/<PID>/ns/timeFor example:
$ readlink /proc/$/ns/time
time:[4026531834]$$ returns the PID of the current process. In my case, the shell.
If two processes have the same number in the brackets, they are in the same namespace.
Unprivileged users can create user namespaces since kernel 3.8, in general. Although some distributions may have included this possibility later. You need CAP_SYS_ADMIN for creating other namespaces.
As you may have noticed, in the hostname example above, as an unprivileged user, I was able to create a user namespace where I’m root. What’s going on? When you create a user namespace, by default, you get all capabilities, including CAP_SYS_ADMIN. That’s why I was able to create the UTS namespace withint the new user namespace too. But what you can do with those capabilities is constrained. We say that the capabilities are namespaced, that means that you can only do actions that affect that namespace, and not other namespaces. So, yes, you are root, but in a limited way. More on this later.
Below I explain what I have researched about the Mount, Process ID, and User ID namespaces. For information about the Network, Interprocess Communication, UTS, Control Groups and Time, please, refer to Wikipedia and the references at the end of the article. I have not researched them and I don’t have nothing to add to the information there. I think the Control Groups namespace may be relevant when analyzing flaws that may trigger a DoS.
Mount (mnt) namespace
The mnt NS isolates the list of mount points. Each process can only see the mount points in the same namespace. Therefore, each process in a different namespace sees a different filesystem (different /proc/<PID>/mounts per each process in a different namespace).
mount(2) and umount(2) will only affect processes in the same mnt NS.
If we try to verify this, we will see that a new mnt namespace already has mount points, and if you do an ls, you can see files that were in the host. Why does this happen if the mount points are supposed to be isolated?
$ unshare -Ur -m bash
# cat /proc/$/mounts
/dev/mapper/fedora_localhost--live-root / ext4 rw,seclabel,relatime 0 0
sysfs /sys sysfs rw,seclabel,nosuid,nodev,noexec,relatime 0 0
securityfs /sys/kernel/security securityfs rw,nosuid,nodev,noexec,relatime 0 0
cgroup2 /sys/fs/cgroup cgroup2 rw,seclabel,nosuid,nodev,noexec,relatime,nsdelegate 0 0
pstore /sys/fs/pstore pstore rw,seclabel,nosuid,nodev,noexec,relatime 0 0
efivarfs /sys/firmware/efi/efivars efivarfs rw,nosuid,nodev,noexec,relatime 0 0
none /sys/fs/bpf bpf rw,nosuid,nodev,noexec,relatime,mode=700 0 0
configfs /sys/kernel/config configfs rw,nosuid,nodev,noexec,relatime 0 0By default, when a namespace is created, the mount table of the parent process is recreated in the child process. After this point, if you mount or unmount anything in the child namespace, it does not affect the parent namespace.
If the new mount namespace is created in a user namespace different from the parent’s user namespace, the new mount namespace is considered less privileged. This has some implications. One of them is that mount flags RS_RDONLY, MS_NOSUID, MS_NOEXEC and “atime” flags cannot be changed in less privileged mount namespaces.
We can see the propagation types of the mounts points with this commands:
$ cat /proc/$/mountinfo
23 65 0:22 / /sys rw,nosuid,nodev,noexec,relatime shared:2 - sysfs sysfs rw,seclabel
24 65 0:5 / /proc rw,nosuid,nodev,noexec,relatime shared:14 - proc proc rw
25 65 0:6 / /dev rw,nosuid shared:10 - devtmpfs devtmpfs rw,seclabel,size=8056916k,nr_inodes=2014229,mode=755
26 23 0:7 / /sys/kernel/security rw,nosuid,nodev,noexec,relatime shared:3 - securityfs securityfs rwIf you write from within a mount namespace, you write to the host filesystem. The mnt NS isolates the mount points, but if they are visible and the user has enough permissions, he can write into the filesystem.
$ unshare -Ur -m bash
# pwd
/home/jdoe
# touch test.txtIn another console…
$ pwd
/home/jdoe
$ ls -l test.txt
-rw-r--r--. 1 jdoe jdoe 0 nov 3 10:19 test.txtSo, the moint namespace doesn’t provide filesystem isolation, only different mount points.
In order to obtain filesystem isolation, containers use overlay filesystems. Podman containers use fuse-overlayfs, while Docker rootful containers use OverlayFS that is a functionality within the kernel. The use of fuse has some security implications.
Overlay filesystems are a kind of file systems formed by different layers. When a user tries to read a file, the system tries to find it in the upper layer. If it doesn’t find it, it looks into the lower layer. If there is a file in the upper layer with the same name as a file in lower layers, the former is used. So, files in the upper layer hide files in the lower layer.
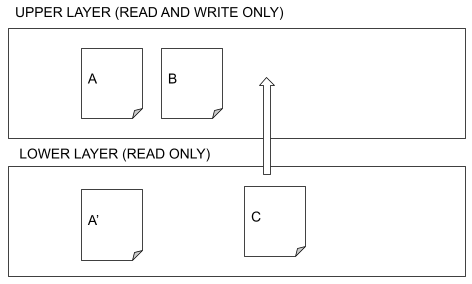
When a file is modified, it is copied to the upper layer, if it does not already exist there.
Deleted files are hidden, but still exist.
Containers mount their own image as the root filesystem, and they are “jailed” with pivot_root or chroot. They are mounted like an overlay with the layers that form the image over it. We can verify this by creating a file in the container and searching the file in the host.
$ podman run -itd ubi8 bash
3a043d6b71a3c3807846b652c8cd0f5dc830709f28599bb2382c1c57544dd65d
$ podman exec -it 3a04 bash
[root@3a043d6b71a3 /]#
[root@3a043d6b71a3 /]# echo "random content" > random_file.txt
$ find . -name random_file.txt 2>/dev/null
./.local/share/containers/storage/overlay/89389ec3e539559ff97eb812bdbbc1b819f05571e3b4c13c93ac81ce1c4e4028/diff/random_file.txt
$ cat ./.local/share/containers/storage/overlay/89389ec3e539559ff97eb812bdbbc1b819f05571e3b4c13c93ac81ce1c4e4028/diff/random_file.txt
random contentThis is also interesting from a forensics point of view: You can examine the host filesytem to examine the container filesystem.
Although the container mounts its own filesystem over /, there are some folders from the host that it needs to work. Remember that containers are not virtual machines, they are just an abstraction based on clever kernel and OS functionalities, but they are just processes executed on a host. The kernel used is the host kernel, so they need some functionality given by the kernel in the form of mount points.
Based on pkg/specgen/generate/oci.go in Podman src and https://github.com/opencontainers/runc/blob/master/libcontainer/SPEC.md, I would say that by default, rootless non-privileged containers mount:
/sys
/dev
/dev/pts
/dev/mqueue
/proc
/dev/shmThen, some routes under these paths are blocked (masked):
/sys/kernel
/proc/acpi
/proc/kcore
/proc/keys
/proc/latency_stats
/proc/timer_list
/proc/timer_stats
/proc/sched_debug
/proc/scsi
/sys/firmware
/sys/fs/selinux
/sys/devOthers might be blocked too, depending on different conditions.
Process ID (pid) namespace
The PID namespace allows each process to have a different PID in each PID namespace, and to have pids that are repeated in different namespaces.
This may be useful, for example, for freezing a container, and resuming its execution in another host. This is possible because PIDs of processes running within the container are isolated.
It also allows to have a PID 1 in each container, which is the first process created in a PID namespace, and receives most of the same special treatment as the normal init process. Most notably that orphaned processes within the namespace are attached to it. The termination of this PID 1 process will immediately terminate all processes in its PID namespace and any descendants [source]:
$ sudo unshare -p -f bash
[sudo] password for jdoe:
# echo $
1PID namespaces are nested [source]. When a new process is created it will have a different PID for each namespace from its current namespace up to the initial PID namespace. The initial PID namespace is able to see all processes. It does not work in the other direction: a process in a child namespace cannot see processes in its parent or higher in the hierarchy [source, source, source]
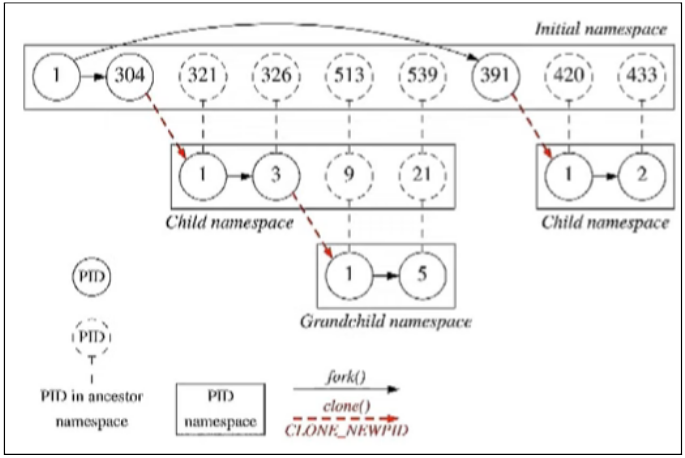
When you execute getpid() you get the PID of the process from the perspective of the current namespace, where the process is running. If you execute getppid(), parent PID, from a process in a child namespace, you will get 0, since the parent is not visible because it is in another namespace.
User ID (user)
Provides both privilege isolation and user identification segregation. What carries privileges in Linux are UIDs and GIDs. By using user namespaces, UIDS and GIDs from a child namespace and a parent namespace are separated in a way that you can be UID 0 within the child namespace, and thus be root within the namespace, but it will correspond to UID 1000 in the parent namespace. That way, outside the container you cannot do anything that requires you to be root.
In fact, the first process executed within a namespace is always root regardless of whether the user who created it was root. BUT, it is root only within the namespace.
A user namespace contains a mapping table converting user IDs from the container’s point of view to the system’s point of view [source]. This allows, for example, the root user to have user id 0 in the container but is actually treated as user id 1000 by the system for ownership checks. A similar table is used for group id mappings and ownership checks. This allows the system to perform the appropriate permission checks when a process in a user namespace performs operations that affect the wider system (e.g., sending a signal to a process outside the namespace or accessing a file).
Mappings are in /proc/<PID>/uid_map and /proc/<PID>/gid_map and consists of one or more lines, each of which contains three values separated by white space:
ID-inside-ns ID-outside-ns lengthID-inside-ns length defines a range of IDs that are going to be mapped to the same number of IDs outside the namespace, starting at ID-outside-ns.
If a user ID has no mapping inside the namespace, then system calls that return user IDs return the value defined in the file /proc/sys/kernel/overflowuid, which on a standard system defaults to the value 65534.
There are rules governing how /proc/<PID>/uid_map and /proc/<PID>/gid_map are modified. You can see more information about these rules here and here.
User namespaces are hierarchical. Each user namespace (other than the initial user namespace) has a parent user namespace, and can have zero or more child user namespaces [source]. The parent of a user namespace is the user namespace of the process that creates the user namespace. A user namespace is created by calling clone(2), unshare(2) or unshare(1). This parental relationship affects how capabilities work in relation to namespaces.
Example:
$ PS1='uns2$ ' unshare -U -r bash
uns2$ cat /proc/$/uid_map
0 1000 1
uns2$ cat /proc/$/gid_map
0 1000 1
uns2$ whoami
root
uns2$ id
uid=0(root) gid=0(root) groups=0(root),65534(nobody) context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
uns2$ echo $ 7707And in another terminal…
$ grep '[UG]id' /proc/7707/status
Uid: 1000 1000 1000 1000
Gid: 1000 1000 1000 1000With this exampe we can review something that we have said. If we are root within the namespace, we would be able to change the hostname:
uns2$ hostname winterfell
hostname: you must be root to change the host nameI get an error. It seems that I cannot change the hostname, but why? I’m root, I should be able to change it…the reason is that the new shell still resides in the old UTS namespace, which is the space that governs hostnames. This means that although you have UID 0 in the new user namespace you only have superuser privileges in objects governed by that new user namespace. All permission checks are done against the process capabilities in the user namespace that owns the non-user namespace. For example, I try to change the hostname by using the bash in the new user namespace. The hostname is an object that resides in UTS namespace, a non-user namespace owned by the parent namespace of the new user namespace. I have not done anything to have a UTS namespace inside the new user namespace, I have not created it. So the permission is checked against the parent namespace where I don’t have the CAP_SYS_ADMIN capability.
$ hostname
localhost.localdomain
$ PS1='uns2$ ' unshare -Ur -u bash
uns2$ hostname
localhost.localdomain
uns2$ hostname winterfell
uns2$ hostname
winterfellIn another console…
$ hostname
localhost.localdomainThat was possible because the new namespace created a new UTS namespace as a child of the new user namespace created with -U where the process is UID 0 and has CAP_SYS_ADMIN capabilities. So when trying to change the hostname the capability is not checked against the initial NS but against the new user namespace.
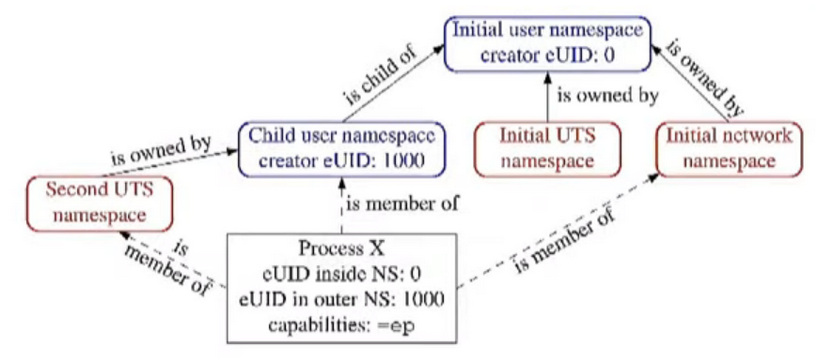
The graph above shows that if we try to execute an operation that requires CAP_NET_ADMIN, it will fail because the network namespace’s parent is still the initial user namespace and not the new namespace.
Executing the line below, you can see in which namespace the process is:
$ readlink /proc/$/ns/userWith that easy verification, we can check if we are in the same namespace or not, for a user namespace or other.
It is possible to see a tree view of the namespaces with this tool:
$ sudo go run namespaces_of.go --namespaces=uts,net 6115 16236
user {4 4026531837} <UID: 0>
[ 6115 ]
uts {4 4026531838}
[ 6115 ]
net {4 4026532008}
[ 6115 16236 ]
user {4 4026532823} <UID: 1000>
[ 16236 ]
uts {4 4026532838}
[ 16236 ]What happens to resources that are not governed by any namespace? For example, loading kernel modules, which require capability CAP_SYS_MODULE. In these cases, the kernel checks the permissions of the process in the initial user namespace where you usually won’t have those capabilities and you won’t be able to load modules.
Control groups
Control groups (cgroups) are another component of Linux containers. Cgroups group processes and implement resource accounting and limiting. They ensure, for example, that a single container cannot bring the system down by exhausting resources like memory, CPU or disk I/O.
I have not researched them, so if you want more information about them, please refer to the references section at the end.
Capabilities
Traditional UNIX privilege theory and practice separate normal user and superusers depending on the UID and GID they have. UID and GID 0 are superusers, and the rest normal users.
We have a way of giving superuser privileges to normal users temporarily. It is the suid bit. If you set the suid bit to an executable, the user executing it acquires the privileges of the owner of the executable, so if the owner is root, it acquires superuser privileges while executing the binary.
Capabilities allow fine-grained access control to resources. With capabilities, no longer is it root or non-root. Capabilities divide the superuser power in 38 different superpowers, which each one is a capability (man capabilities). For example, for binding a port below 1024 you used to need root. With capabilities you don’t need to be root. You just need to have the capability CAP_NET_BIND_SERVICE. Capabilities is a way to give some permissions that before only root had, to unprivileged users.
Instead of using the suid bit on an executable, we can add the capabilities needed with setcap(), which needs CAT_SETFCAP capability. Users and files can have capabilities. If a file has a capability it can give it to the process it creates.
Capabilities are (almost all) user namespaced. This means that when I check, do I have this capability? The real question is, do I have this capability in the current user namespace? However, this is not true for some capabilities. There are privileged operations that affect resources that are not associated with any namespace type, for example, loading a kernel module (governed by CAP_SYS_MODULE), or creating a device (governed by CAP_MKNOD). Only a process with privileges in the initial user namespace can perform such operations.
As we have said, a user namespace have all capabilities enabled (although constrained to the namespace). However, rootless containers don’t work the same. They drop many capabilities from the process, and only give these:
CAP_CHOWN
CAP_DAC_OVERRIDE
CAP_FSETID
CAP_FOWNER
CAP_MKNOD
CAP_NET_RAW
CAP_SETGID
CAP_SETUID
CAP_SETFCAP
CAP_SETPCAP
CAP_NET_BIND_SERVICE
CAP_SYS_CHROOT
CAP_KILL
CAP_AUDIT_WRITESource: https://github.com/moby/moby/blob/46cdcd206c56172b95ba5c77b827a722dab426c5/oci/caps/defaults.go#L4
Containers support the addition and removal of capabilities when the container is launched.
Seccomp
Seccomp is a Linux security feature that allows to filter which syscalls a process is allowed to make. The default seccomp profile provides a sane default for running containers with seccomp and allows around 150 system calls out of 450 approximately [source]
Both Podman and Docker have a predefined list of syscalls that are filtered. Seccomp default configuration, for Podman and Fedora, is here /usr/share/containers/seccomp.json).
SELinux
SELinux is basically a label system where:
- Every process has a label
- Every file, directory and system object has a label
- Policy rules control the interaction between labeled processes and labeled objects.
- The kernel enforces these rules.
By using SELinux type enforcement, container processes can only read/execute /usr files. And they can only write to container files. Lots of CVEs are mitigated by this SELinux policy. For example, CVE-2015-3629 or CVE-2015-9962.
The container processes have this process type: container_t.
Container files have this file type: container_file_t.
If you mount / at /host within a container, you won’t be able to read or write anything because of SELinux. You also would be able to see the blocks in SELinux logs.
$ sudo podman run -e --rm -ti -v /:/host rhel7
bash-4.2# cd /host
bash-4.2# touch test1.txt
touch: cannot touch 'test1.txt': Permission denied
$ sudo ausearch -ts recent|grep denied
[sudo] password for jdoe:
type=AVC msg=audit(1604064728.542:626): avc: denied { write } for pid=14512 comm="touch" name="/" dev="dm-1" ino=2 scontext=system_u:system_r:container_t:s0:c352,c1005 tcontext=system_u:object_r:root_t:s0 tclass=dir permissive=0The combination of namespaces, specially user namespaces, the overlay filesystems, rootless container defaults, capabilities, seccomp, and SELinux is crucial. AFAICU, namespaces extend the attack surface making it possible for namespaced root users to access parts of the kernel, syscalls surface, they hadn’t access before user namespaces. Kernel logic prevents that malicious namespaced (virtual) root users to do something wrong, but that logic can have bugs now, or in the future. I don’t think that anything is wrong with this, but a risk we should be aware.
Privileged containers
I extracted a big part of the concepts of this section from this article by Dan Walsh, one of the greatest experts on containers and Podman.
Privileged containers are those run with the –privileged option. The privileged option does not add special permissions to rootless containers. The main thing that –privileged do is to not apply some hardening or isolation mechanisms to the container, allowing it to have more interactions with the host. Those interactions would be blocked by different default container mechanisms, but if you launch it as privileged, those mechanisms are not used.
This changes the attack surface of a container, and something that may not be an issue in a rootless regular container, could be a vulnerability in a privileged container.
A privileged container is a container that runs without some isolation mechanisms from the host. So, if you are root within a container and you run that container as privileged, you are root in the host. But what happens if you run a rootless privileged container? –privileged is not unconfined or full root access to the host system. If you are using –privileged over a rootless container you will still be limited by what the user executing the container can do. For example, if using a non-root user for executing a container with –privileged, you won’t be able to publish a port below 1024, as non-root users cannot do that.
What are the isolation mechanisms that are not applied with using –privileged?
Read-only kernel filesystems
Kernel file systems provide a mechanism for a process to alter the way the kernel runs. For example, with sysctl, you can change certain kernel parameters at runtime (sysctl). They also provide information to processes on the system. By default, we don’t want container processes to modify the kernel, so we mount some kernel filesystems as read-only within the container. The read-only mounts prevent privileged processes and processes with capabilities in the user namespace to write to those the kernel file systems. If a container runs with –privileged, these mount points are not mounted read-only.
$ podman run ubi8 mount | grep '(ro'
sysfs on /sys type sysfs (ro,nosuid,nodev,noexec,relatime,seclabel)
cgroup2 on /sys/fs/cgroup type cgroup2 (ro,nosuid,nodev,noexec,relatime,seclabel,nsdelegate)
tmpfs on /proc/acpi type tmpfs (ro,relatime,seclabel,size=0k,uid=1000,gid=1000)
tmpfs on /proc/scsi type tmpfs (ro,relatime,seclabel,size=0k,uid=1000,gid=1000)
tmpfs on /sys/firmware type tmpfs (ro,relatime,seclabel,size=0k,uid=1000,gid=1000)
tmpfs on /sys/fs/selinux type tmpfs (ro,relatime,seclabel,size=0k,uid=1000,gid=1000)
tmpfs on /sys/dev type tmpfs (ro,relatime,seclabel,size=0k,uid=1000,gid=1000)
proc on /proc/asound type proc (ro,relatime)
proc on /proc/bus type proc (ro,relatime)
proc on /proc/fs type proc (ro,relatime)
proc on /proc/irq type proc (ro,relatime)
proc on /proc/sys type proc (ro,relatime)
proc on /proc/sysrq-trigger type proc (ro,relatime)
$ podman run --privileged ubi8 mount | grep '(ro'
$| Regular Rootless | Privileged Rootless |
| Some kernel filesystems (e.g. /proc/sys) are mounted read-only. | All kernel filesystems are mounted as is. |
Masking over kernel filesystems
In regular rootless containers, /proc is not mounted read-only because it is namespace aware, and thus can differentiate if the change should be allowed or not, depending on the user namespace. However, some directories within /proc should be protected against reading and writing from within the container. In these cases, the container engines mount tmpfs file systems over potentially dangerous directories, preventing processes inside of the container from using them.
$ podman run ubi8 mount | grep /proc.*tmpfs
tmpfs on /proc/acpi type tmpfs (ro,relatime,seclabel,size=0k,uid=1000,gid=1000)
devtmpfs on /proc/kcore type devtmpfs (rw,nosuid,seclabel,size=8056916k,nr_inodes=2014229,mode=755)
devtmpfs on /proc/keys type devtmpfs (rw,nosuid,seclabel,size=8056916k,nr_inodes=2014229,mode=755)
devtmpfs on /proc/latency_stats type devtmpfs (rw,nosuid,seclabel,size=8056916k,nr_inodes=2014229,mode=755)
devtmpfs on /proc/timer_list type devtmpfs (rw,nosuid,seclabel,size=8056916k,nr_inodes=2014229,mode=755)
devtmpfs on /proc/sched_debug type devtmpfs (rw,nosuid,seclabel,size=8056916k,nr_inodes=2014229,mode=755)
tmpfs on /proc/scsi type tmpfs (ro,relatime,seclabel,size=0k,uid=1000,gid=1000)
$ podman run --privileged ubi8 mount | grep /proc.*tmpfs
$What we need to know about a kernel flaw to evaluate if it can be exploited within a container, and may affect the host
| Regular Rootless | Privileged Rootless |
| Some directories within kernel filesystems (e.g. /proc/acpi) are masked to protect them. | All kernel filesystems are mounted as is. |
Linux capabilities
A root user within a regular rootless container has all capabilities. But these capabilities are namespaced, that as we have explained, are limited to whatever can be done within the user namespace. However, a regular rootless container has a limited number of capabilities in the host user namespace. When you run a container as privileged, capabilities are not limited.
$ podman run -d ubi8 sleep 100
641c48e3f659d19d8a02f21ea4bf8fbe365a737ec209e9e6934f2275ac089ff3
$ podman top -l capeff
EFFECTIVE CAPS
AUDIT_WRITE,CHOWN,DAC_OVERRIDE,FOWNER,FSETID,KILL,MKNOD,NET_BIND_SERVICE,NET_RAW,SETFCAP,SETGID,SETPCAP,SETUID,SYS_CHROOT
$ podman run --privileged -d ubi8 sleep 100
17a79deabf9bed3500b1989a38299a2bf10519d6554c9a13fe3388fd447f2424
$ podman top -l capeff
EFFECTIVE CAPS
fullSeccomp – Syscall filtering
With –privileged, usual syscalls that are dropped within containers, are not dropped. So the attack surface is bigger.
SELinux
As we have seen previously, containers engines launch container processes with a single confined SELinux label, usually container_t, and the elements within the container with the label container_file_t. The SELinux policy says that the container_t processes can interact only with container_file_t resources.
If the container is run as –privileged, the container processes are run as unconfined_u, and no additional segregation is added by SELinux.
$ podman run -d ubi8 sleep 100
5e8c1764fb88c2efe59e2483c5e5a5c1e86eaf02990a85396941a4d10366e973
$ podman top -l label
LABEL
system_u:system_r:container_t:s0:c221,c298
$ podman run --privileged -d ubi8 sleep 100
0bf4e3300d4d596ef7dade9a483ba547777a394acafb75088fc8f6131c4f28fd
$ podman top -l label
LABEL
unconfined_u:system_r:container_runtime_t:s0Namespaces
The –privileged flag does not affect namespaces. The segregation contributed by namespaces is still there. So, for example, from within a privileged container, you are not able to see processes outside the container.
Conclusions about privileged containers
Privileged containers are not like executing a container as root and without any restriction. It is true that the security is much lower because the attack surface is much bigger, but if we have to analyze the risk of a flaw over a privileged container, we have to understand which attack vector the flaw uses, and if it is one of the elements that change in a privileged container or not.
Super Privileged containers
A “super privileged” container is a term coined by Dan Walsh, and describes a container that is run with the minimum functionality to continue naming it a container, but with almost all the segregation from the host removed.
These are “needed” sometimes for containers intended to access, monitor, and possibly change features on the host system directly. These are referred to as super privileged containers.
The difference between a privileged and a super privileged container is that the second uses only the mnt NS. For the rest of namespaces it uses the same as the host.
A super privileged container is run like this:
docker run -it --name rhel-tools --privileged \
--ipc=host --net=host --pid=host -e HOST=/host \
-e NAME=rhel-tools -e IMAGE=rhel7/rhel-tools \
-v /run:/run -v /var/log:/var/log \
-v /etc/localtime:/etc/localtime -v /:/host rhel7/rhel-tools- -i runs it interactively
- -t opens a terminal
- –name sets the name of the container
- –privileged explained in a previous section
- –ipc=host, –net=host, and –pid=host turn off the ipc, net and pid namespaces, thus eliminating the isolation between the container and the host. This means that the processes within the container see the same network and process table, as well as share any IPCs with the host processes.
- -e <env_variable=value> sets environment variables within the container
- -v /run:/run mounts the /run directory from the host on the /run directory inside the container. This allows processes within the container to talk to the host’s dbus service and talk directly to the systemd service.
- -v /var/log:/var/log allows commands run within the container to read and write log files from the host’s /var/log directory.
- -v /etc/localtime:/etc/localtime Causes the host system’s timezone to be used with the container.
- -v /:/host Mounting / from the host on /host allows a process within the container to easily modify content on the host. Running touch /host/etc/passwd would actually act on the /etc/passwd file on the host.
Any process run within a super privileged container is very similar to a process run directly in the host. Only use them if it is absolutely necessary and before that evaluate deeply the risk to the business.
What we need to know about a kernel flaw to evaluate if it can be exploited within a container, and may affect the host
In general,
- If the user needs any capability to arrive and exploit that vulnerable source code.
- Which syscalls give a user access to that vulnerable code.
- In order to evaluate if it is mitigated or not, which host resources are affected by the flaw and if SELinux blocks access to them.
Depending on the vulnerability, many other things.
I don’t know if this is easy or difficult to know for each kernel flaw, but I think it is information that we need for analyzing flaws and that we will need to gather.
Conclusions
- Containers are basically processes that use some clever kernel and OS functionalities for implementing isolation and the abstraction of “containers”.
- At low level, how they work depend on the implementation, the kernel version in use and the Linux distro.
- As containers use the same kernel as the host, vulnerabilities on the kernel may break the isolation. The different security functionalities in use help mitigate this risk, but it is there.
- Rootless containers provide much more security than rootful containers. At the end, rootless containers will take over the position of rootful containers and rootful containers will be only users when rootless containers cannot be used.
- That the containers have this functionality doesn’t mean that container orchestrators implement them or are mature enough for production.
References
- https://developers.redhat.com/blog/2020/09/25/rootless-containers-with-podman-the-basics/
- https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux_atomic_host/7/html-single/managing_containers/index?extIdCarryOver=true&sc_cid=7013a000002gYn7AAE#set_up_for_rootless_containers
- https://github.com/containers/podman/blob/master/rootless.md
- https://docs.docker.com/engine/security/
- https://unit42.paloaltonetworks.com/rootless-containers-the-next-trend-in-container-security/
- https://www.redhat.com/sysadmin/privileged-flag-container-engines
- https://www.redhat.com/sysadmin/behind-scenes-podman
- https://www.youtube.com/watch?v=_w6H5yAbGj8
- https://www.redhat.com/sysadmin/rootless-podman-makes-sense
- https://opensource.com/article/18/12/podman-and-user-namespaces
- https://medium.com/@jessgreb01/what-is-the-difference-between-a-process-a-container-and-a-vm-f36ba0f8a8f7
- https://lwn.net/Articles/532593/
- https://indico.cern.ch/event/757415/contributions/3421994/attachments/1855302/3047064/Podman_Rootless_Containers.pdf
- https://en.wikipedia.org/wiki/Linux_namespaces
- https://www.youtube.com/watch?v=-PZNF8XDNn8
- https://www.youtube.com/watch?v=73nB9-HYbAI&t=885s
- https://www.youtube.com/watch?v=0kJPa-1FuoI
- https://www.redhat.com/sysadmin/user-namespaces-selinux-rootless-containers
- https://www.youtube.com/watch?v=FOny29a31ls
- https://man7.org/linux/man-pages/man7/mount_namespaces.7.html
- http://libfuse.github.io/doxygen/fast17-vangoor.pdf
- https://www.youtube.com/watch?v=x1npPrzyKfs
- https://developers.redhat.com/blog/2014/11/06/introducing-a-super-privileged-container-concept/
